
canal foot bridge interior architecture
Read the related Technical Perspective
Numerous microarchitectural optimizations unlocked tremendous processing power for deep neural networks that in turn fueled the AI revolution. With the exhaustion of such optimizations, the growth of modern AI is now gated by the performance of training systems, especially their data movement. Instead of focusing on single accelerators, we investigate data-movement characteristics of large-scale training at full system scale. Based on our workload analysis, we design HammingMesh, a novel network topology that provides high bandwidth at low cost with high job scheduling flexibility. Specifically, HammingMesh can support full bandwidth and isolation to deep learning training jobs with two dimensions of parallelism. Furthermore, it also supports high global bandwidth for generic traffic. Thus, HammingMesh will power future large-scale deep learning systems with extreme bandwidth requirements.
Artificial intelligence (AI) is experiencing unprecedented growth providing seemingly open-ended opportunity. Deep learning models combine many layers of operators into a complex function that is trained by optimizing its parameters to large datasets. Given the abundance of sensor, simulation, and human artifact data, this new model of designing computer programs, also known as data-driven programming or “software 2.0”, is mainly limited by the capability of machines to perform the compute- and data-intensive training jobs. In fact, the predictive quality of models improves as their size and training data grow to unprecedented scales.15 Building deep learning supercomputers, to both explore the limits of artificial intelligence and commoditize it, is becoming not only interesting to big industry but also humanity as a whole.
A plethora of different model types exist in deep learning and new major models are developed every two to three years. Yet, their computational structure is similar—they consist of layers of operators and they are fundamentally data-intensive.14 Many domain-specific accelerators take advantage of peculiarities of deep learning workloads be it matrix multiply units (“tensor cores”), specialized vector cores, or specific low-precision datatypes. Those optimizations can lead to orders of magnitude efficiency improvements. Yet, as we are approaching the limits of such microarchitectural improvements, we need to direct our focus to the system level.
Today’s training jobs are already limited by data movement.14 In addition, trends in deep neural networks, such as sparsity, further increase those bandwidth demands in the near future.9 Memory and network bandwidth are expensive—in fact, they form the largest cost component in today’s systems. Standard HPC systems with the newest InfiniBand adapters can offer 400Gb/s but modern deep learning training systems offer much higher bandwidths. Google’s TPUv2, designed seven years ago, has 1Tbps off-chip bandwidth, AWS’ Trainium has up to 1.6Tbps per Tm1n instance, and Nvidia A100 and H100 chips have 4.8 and 7.2Tbps (local) NVLINK connectivity, respectively. The chips in Tesla’s Dojo deep learning supercomputer even have 128Tbps off-chip bandwidth—more than a network switch. Connecting these extreme-bandwidth chips at reasonable cost is a daunting task and today’s solutions, such as NVLINK, provide only local islands of high bandwidth.
We argue that general-purpose HPC and datacenter topologies are not cost-effective at these endpoint injection bandwidths. Yet, workload specialization, similar to existing microarchitectural optimizations, can lead to an efficient design that provides the needed high-bandwidth networking. We begin with developing a generic model that accurately represents the fundamental data movement characteristics of deep learning workloads. Our model shows the inadequacy of the simplistic view that the main communication in deep learning is allreduce. In fact, we show that communication can be expressed as a concurrent mixture of pipelines and orthogonal reductions forming toroidal data movement patterns. This formulation shows that today’s HPC networks, optimized for full global (bisection) bandwidth, are inefficient for deep learning workloads. Specifically, their global bandwidth is overprovisioned while their local bandwidth is underprovisioned.
We use our insights to develop HammingMesh, a flexible topology that can adjust the ratio of local and global bandwidth for deep learning workloads. HammingMesh combines ideas from torus and global-bandwidth topologies (for example, fat tree) to enable a flexibility-cost tradeoff shown schematically in Figure 1. Inspired by machine learning traffic patterns, HammingMesh connects local high-bandwidth 2D meshes using row and column (blue and red) switches into global networks.a
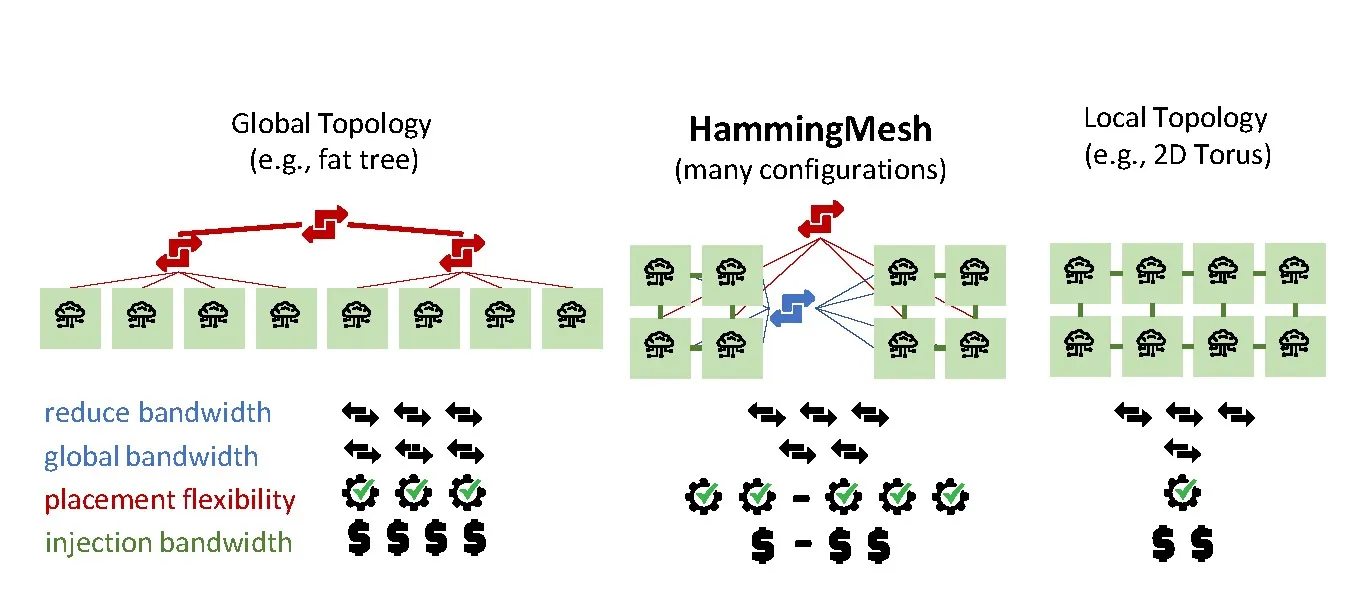
In summary, we show how deep learning communication can be modeled as sets of orthogonal and parallel Hamiltonian cycles to simplify mapping and reasoning. Based on this observation, we define principles for network design for deep learning workloads. Specifically, our HammingMesh topology
With those principles, HammingMesh enables extreme off-chip bandwidths to nearest neighbors at more than 8x cheaper allreduce bandwidth compared to standard HPC topologies such as fat trees. HammingMesh reduces the number of external switches and cables and thus reduces overall system cost. Furthermore, it provides significantly higher flexibility than torus networks. HammingMesh also enables seamless scaling to larger domains without separation between on- and off-chassis programming models (like NVLINK vs. InfiniBand). And last but not least, we believe that HammingMesh topologies extend to other machine learning, (multi)linear algebra, parallel solvers, and many other workloads with similar traffic characteristics.